Fine-Tuning a pre-trained LLM with unlabelled dataset
A generic LLM or an LLM pre-trained on the dataset different from the domain of the final task has to be fine-tuned to the task specific dataset. There are already many articles, blogs and papers that talks about why such a fine-tuning is required. Here we will assume that the reader knows why is fine-tuning or transfer learning important and focus on leveraging the unlabelled dataset for fine-tuning.
Here are some quick reminders before proceeding to the fine-tuning section:
- Adaptation to the domain: The LLM might have been trained on public dataset like wikipedia or the books, it won’t be useful (or it will hallucinate) without fine-tuning as the final task dataset could be private and never seen by the model before.
- One should always try few-shot and zero-shot learning before fine-tuning to have an idea on which model to choose for the final task as well as how much domain specific data might be required for fine-tuning.
- For tasks such as RAG (Retriever Augmented Generation), one gives the context to the LLM to receive the answers to the questions. One could have argued to fine-tune on all the pdf documents but with RAG technique, it is not required to fine-tune.
Even after considering few-shot learning, zero-shot learning and considering techniques like RAG, one has to fine-tune on the task specific dataset.
Note the difference between few/zero-shot learning and fine-tuning is that the model parameters or weights are changed only after fine-tuning and not during few/zero-shot learning.
Ideally, a labelled dataset is like the golden dataset both for the training as well as evaluation. But more often than not, we either don’t have the dataset or just have the unlabelled set.
The goal of fine-tuning is to adapt to the domain, which should be possible with the domain specific dataset whether labelled or unlabelled.
Here are the three ways in which unlabelled data can be used:
A two step process
- Domain Adaptation: First we adapt the pre-trained model like BERT to the task domain by training the model on the domain specific unlabelled data. Just like BERT is trained on unsupervised data using MLM, we can also do the same with our unlabelled dataset using MLM technique, language model objective of predicting masked words. Now such a model adapted to our domain can be reused for multiple purposes. To do this we need to take care of the tokenisation step by masking the random tokens and making sure they are not used in calculating the loss. Refer to this notebook to see how this was done using the data collator function during the run time.
- Fine-Tuning for task like classification: Here we load the adapted model as a classifier and fine-tune it. This fine-tuning is like usual training of a neural network using transfer learning with labelled data. The trick here was domain adaptation that should provide a boost to the model’s performance with unlabelled data and little effort(of masked language modeling and the fine-tuning it with little labelled data).
Note that if you enough or huge labelled data, domain adaptation with unlabelled step is not required
Unsupervised Data Augmentation(UDA)
Ensuring the model consistency for inference is also part of the model training that is usually covered as part of the regularisation techniques. This is what UDA focusses on, the model consistency for the predictions to be made.
Simple Idea: In UDA, one takes the unlabelled sample and a slightly distorted version of the sample using techniques like back translation or token replacement. If the model is consistent, it should ideally give the same classification for both the original and the distorted sample. This consistency is enforced by minimising the KL-divergence between the predictions of the original sample and the distorted one. As shown in the below figure, while the labelled data is used to train the usual supervised cross-entropy loss and the unlabelled data is used to ensure the model consistency.
Note that reducing model consistency in a way is a regularisation step as model overfitting happens due to high variance which indirectly means model is inconsistent in its predictions.
This is more clear in this blog on bias and variance error.

This approach is so good that a BERT model trained with UDA gave similar performance when trained on a few labelled samples as compared to training without UDA on thousands of labelled samples. Although, the training time is increased due to the extra step in the form of data augmentation pipeline leading to multiple forward passes for unlabelled and augmented samples.
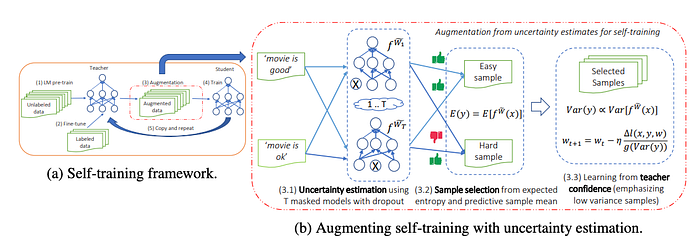
Uncertainty-Aware self-training(UST)
This method is somehow inspired from the gradient boosting ensemble method and also an active learning approach. One starts with the first teacher model trained on the initial labelled data. Teacher model predict labels or pseudo labels for the unlabelled data. Then another student model is trained with the pseduo-labels generated in the previous step by the teacher model. Then this student model becomes the teacher model in the next iteration and this leg continues.
Whats interesting about UST: The uncertainty measure is estimated by feeding the same sample multiple times with dropout turned on. The variance in the predictions gives a proxy for the certainty of the model. This uncertainty measure is used to sample the pseudo-labels using the method called Bayesian Active Learning by Disagreement(BALD). UST performs better than the UDA method on multiple datasets and can get closer to the model performance that is otherwise achieved with large number of labelled samples.
There is no denying that labelled dataset is not required for fine-tuning. At least for evaluating the fine-tuned model, only labelled data will be useful. Of course, if the final tasks are MLM(Masked Language Model) or NSP(Next Sentence Prediction), even the unlabelled data is useful for evaluation. By leveraging the unlabelled dataset, one can reduce the requirement for the quantity of labelled data required, both for domain adaptation and then fine-tuning for classification or similar tasks.